AWS Costs
Just trying to keep a lid on things
Created by Laurence J MacGuire a.k.a. 刘建明 a.k.a Liu Jian Ming
ThoughtWorks XiAn, 2017/02/17

Saving Costs
Usually simple. Just requires some effort.
What you need to know
- What your application requirements are
- How AWS prices their services
- Which services you are using, and how, for how much
How it’s done
- Low Hanging Fruit
- Resize all the things
- Cost-Optimise / Re-architecture
Be In The Know
First: Your Costs
Check out the billing console.
Month To Date & Estimate
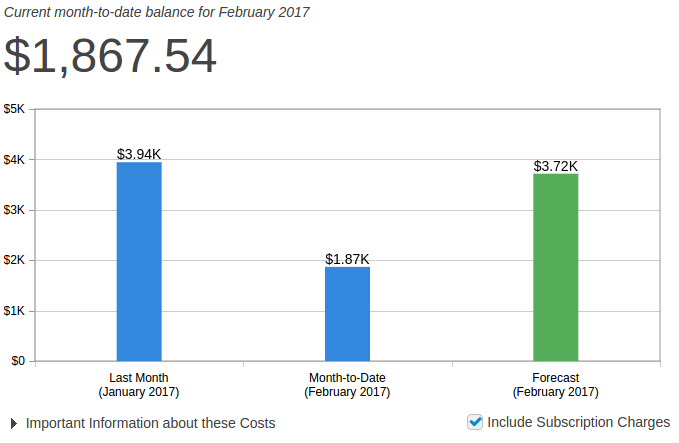
Last Month Costs, This Month (so far), This Months Forecast
Month To Date Breakdown
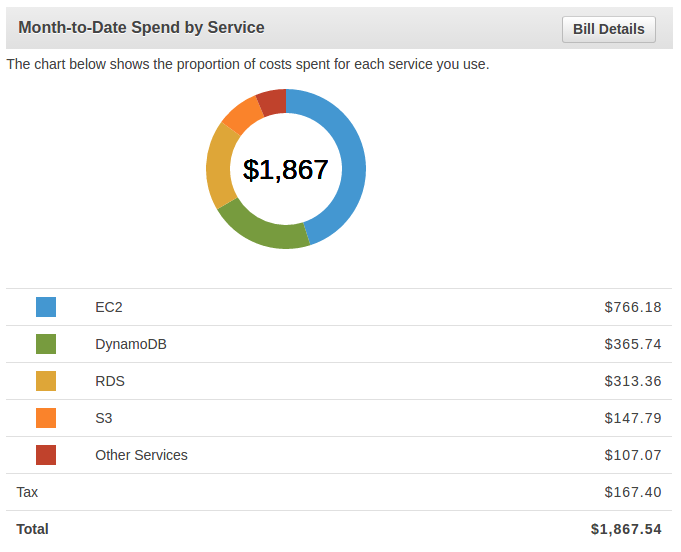
Yeah. We spent a lot.
Also
Checkout CloudWatch IN US-EAST-1
CloudWatch > Metrics > Billing
All > Billing > By Service
Select All
Billing Metrics!
Point In Time Invoice Estimate
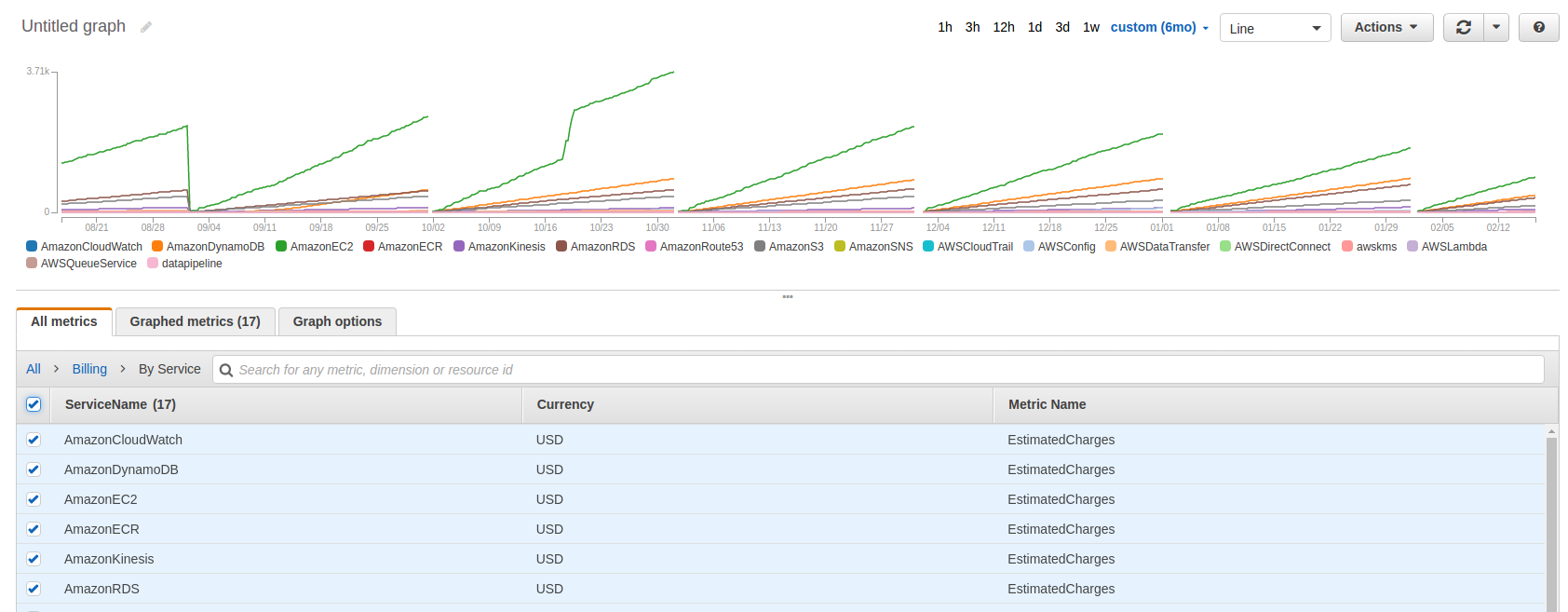
Someone Screwed Up
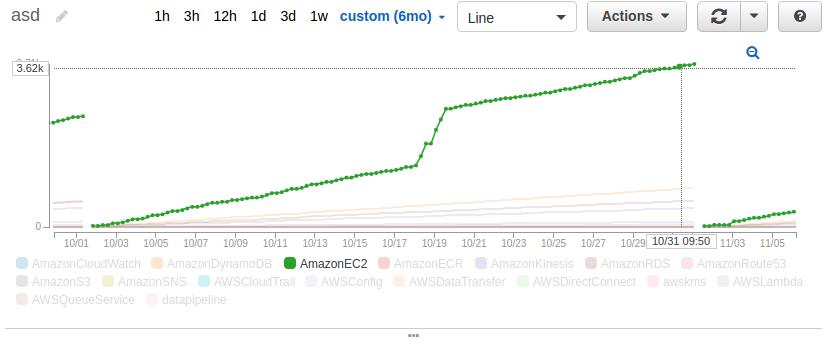
An extra 1200$? It was me :(
Second: AWS Pricing
Pretty much all the pricing can be accessed from here:
Elastic Compute Cloud
EC2: Compute Capacity
- AWS EC2 Instances are a cost per hour
- They round everything up to one hour
- Instance types range from nano to ?xlarge
- Instance classes support different workload types
EC2: For Example
M class instances are general purpose
T class instances have burstable capacity
R class have high memory / lower CPU
C class have high CPU / lower memory
EC2: For Example
- t2.nano => 0.008$ /hour
- r3.large => 0.2$ /hour
ap-southeast-2 pricing
EC2: Storage
- AWS Instance can have persistent storage (EBS)
- Minimum size: 8GB
- Minimum price: 0.10$ /gig /month
- Minimum: 0.80$ / instance / month (if using them)
EC2: Networking
- Incoming: free or 0.01$ /gig
- Outgoing: 0.14$ /gig
It’s more complicated. But that’s the idea.
EC2: Load Balancing
- 0.025$ /hour or 18$ /month
- Additional network traffic fees
RDS: Same as EC2 + X%
Similar to EC2.
- Cost per hour
- License cost
- Additional ‘convenience fee’
S3: Object Storage
Simple Pricing: 0.020$ to 0.025$ /gig /month
Watch out for versioning!
More Importantly
Your Apps
Questions worth asking
- How much does it cost?
- What does it do?
- How much of it does it do?
- Do you have an SLA?
How Much Does It Cost?
- AutoScalingGroup
- min: 2, max: 8
- but in reality?
- LoadBalancer
- Fixed fee
Enable ASG Metrics and see GroupTotalInstances
Instance Price * Instance hours = ASG Price
Other dependencies?
- RDS?
- DynamoDB?
Use Cloudwatch and do some Math
What Does It Do?
Know your app. Is it CPU intensive? Is memory or I/O intensive?
I can’t answer these questions. But it’s critical that you know.
How much of it does it do?
How much traffic does it see?
1 RPM? 10 RPM? 100 RPM? 1000 RPM? 10000 RPM?
Do some Math
Do the numbers make sense?
Simple CRUD app w/ 10 RPM? On 8 instances?
Look at all the numbers, and ask yourself.
Doesn’t Make Sense?
- Maybe your infrastructure has issues
- Maybe your code has issues
Investigate.
SLA
You NEED an SLA.
And the means to measure.
Every change is weighing trade-offs. What is acceptable?
1: Re-sizing Infrastructure
- Do you have too much free memory?
- Are your CPUs idling?
Re-size your stuff.
Example: CPU under-utilised
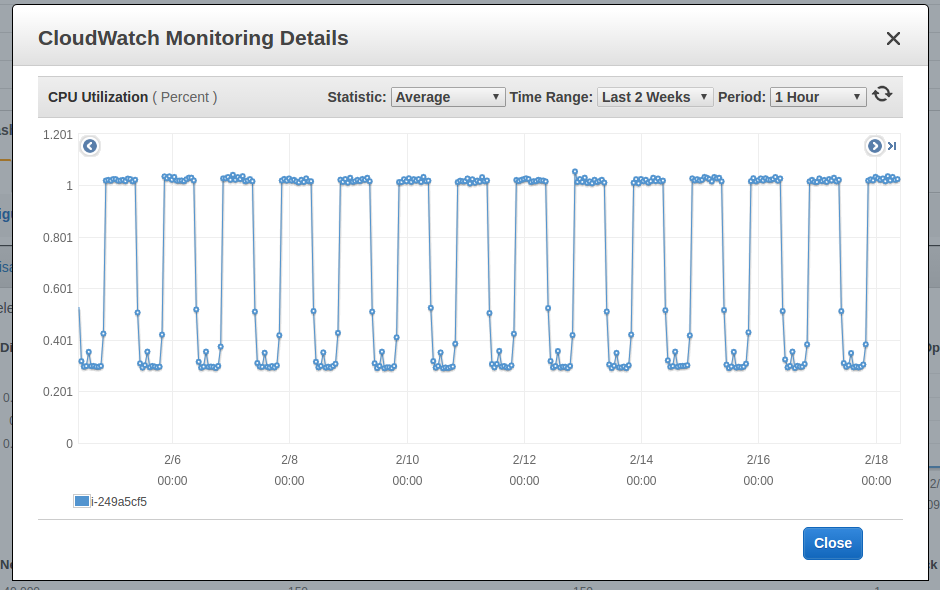
EC2 Instance Console: Monitoring
Example: Network under-utilised
EC2 Instance Console: Monitoring
Example: Disk under-utilised
EC2 Instance Console: Monitoring
Example: Metrics By ASG
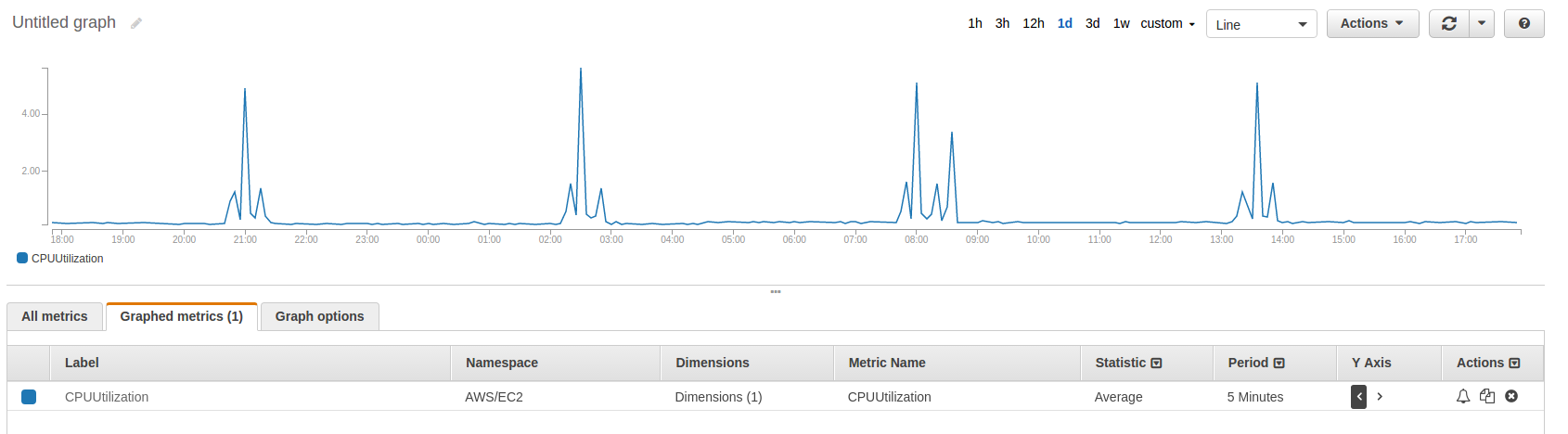
Clouwatch > Metrics > EC2 > By-ASG > CPUUtilization
How?
- Look at ec2instance.info
- Choose the next smaller instance
- Open a PR, ask your Ops peep
- Re-Deploy
- Wait a couple days and try again
Use Case: International / Hash
Before
- ~25 instances
- 20 000$ / month on EC2
Use Case: International / Hash
- Re-sized everything after over provisioning
- Reserved Instances
Use Case: International / Hash
After
- ~20 instances
- 8000$ / month on EC2
2: Profile your app
This code is perfect.
– said no one ever
Chances are, there are easy optimisations you can do.
Examples / Low Hanging Fruit
- I/O related issues
- Not enough threads?
- No caching?
- N+1 problems?
- Wasting time in silly loops?
- sleep(10)?
“Premature optimisation blah blah”
Use Case: Investor
Mostly READ ONLY Database after a large data processing pipeline.
Use Case: Investor
Before
- 8x m3.large rails servers
- m3.xlarge RDS instance
- ~ $1300 /month
Use Case: Investor
- Introduce NGinx level http caching
- MyQL tuning + query tuning
Use Case: Investor
After
- 2x m3.large Rails servers
- m3.large RDS instance
- ~ $500 /month
Not anymore. Since data-services is hammering us :(
Re-Write/Architecture
- Offline processing + S3 (hipster batch)
- Lambda + API Gateway
- SQS instead of ActiveMQ/MySQL/Whatever
- Deferred processing (transaction log / CQRS)
How? Spot Instances
Bid % of normal price. Uptime not garanteed.
Low SLA? Offline processing? Can survive delays?
Try a Spot instance.
Examples: event processors, CI agents, dashboards, report runners …
Use Case: lmac’s logstash
All events come into AWS Kinesis. Get buffered for 7 days. State stored in DynamoDB.
Spot instance is up 95%+ of the time for 30% of the price.
Use Case: lmac’s logstash
Before
- 1x c4.large (0.10$ /hour)
Use Case: lmac’s logstash
After
- 1x c4.xlarge SPOT (~0.03$ /hour)
Low Hanging Fruit
Trusted Advisor
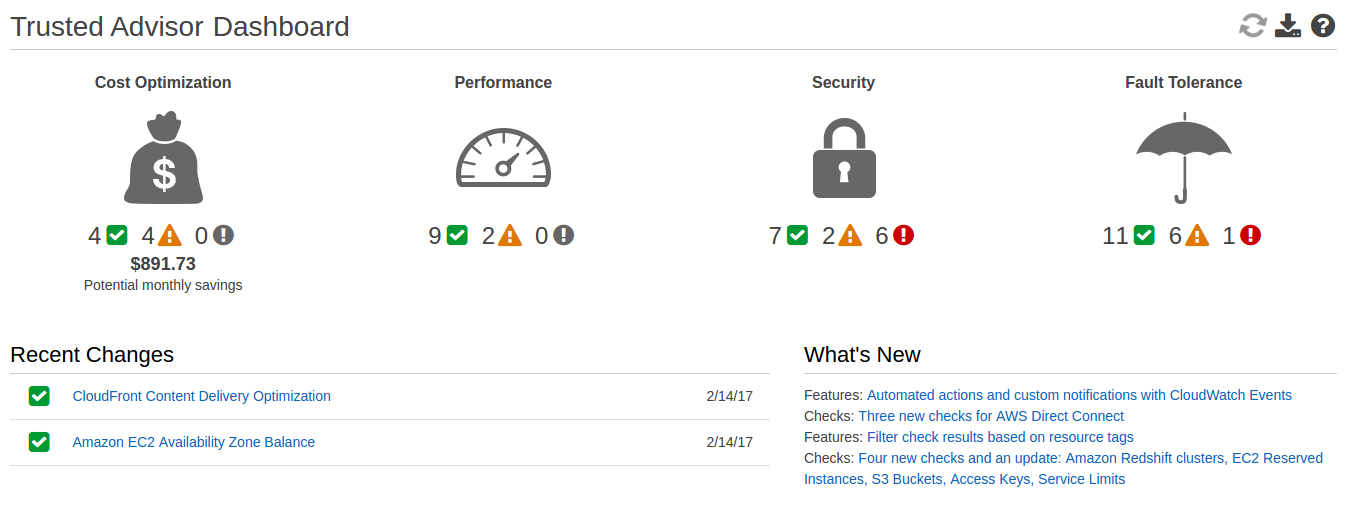
Low Hanging Fruit
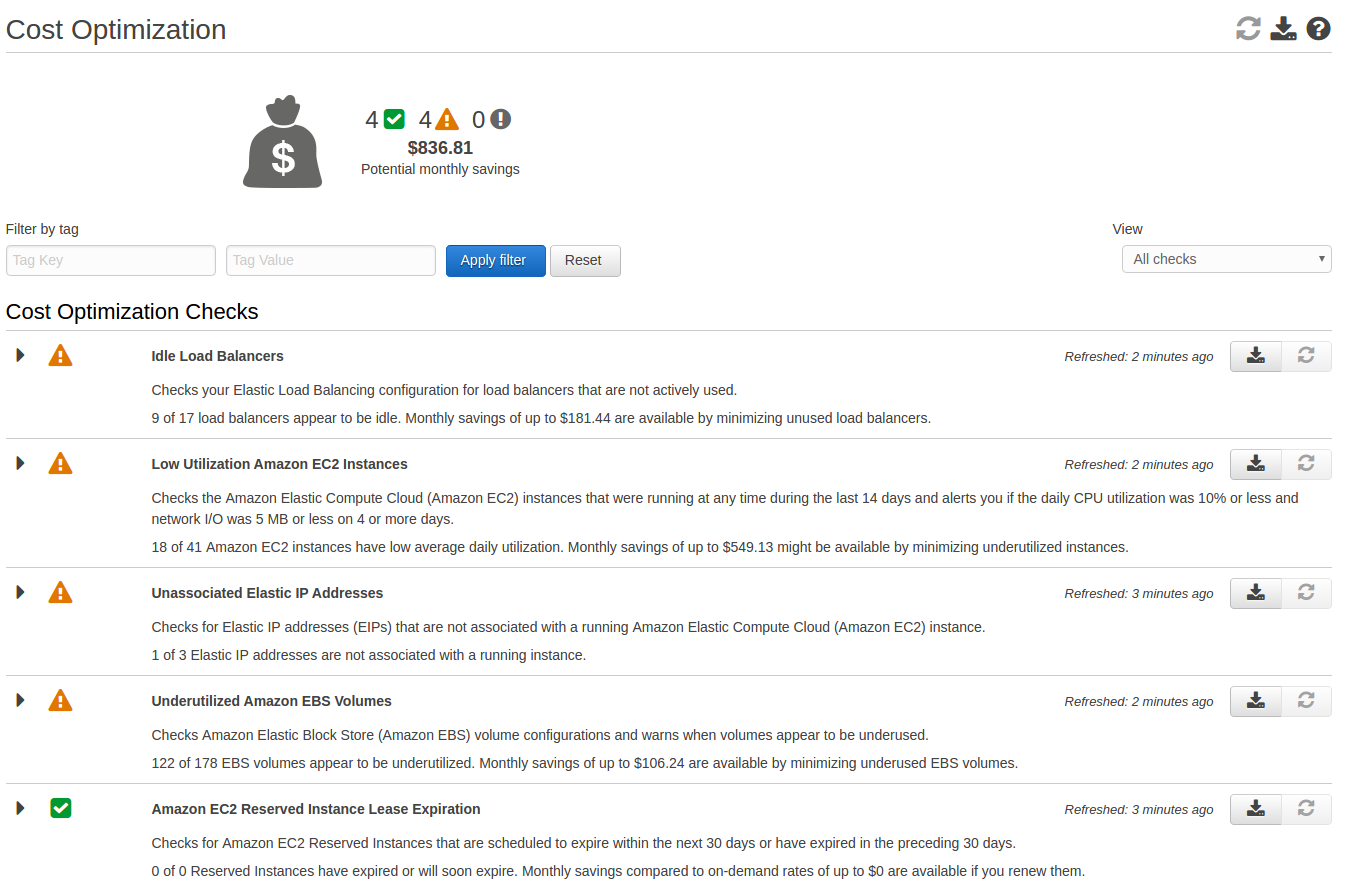
More Tools
CPU Utilisation
$ authenticate
$ ./auto/ec2-utilisation --summary
...
Stat Min Avg Max σ
Instances 23 31 40.0 7.1
vCPUs avail 33 45 60.0 11.2
vCPUs used 2 3 10.8 1.5
Util % 6 8 19.3 2.0
Tells you average CPU usage across an entire account.
Under 20% and you’re really under-utilizing
Stack Costs
$ authenticate
$ ./auto/stack-costs
---
stack: tlap-demo
since: 2017-02-16 05:42:46.765942071 Z
cost:
since: 0.8240000000000001
per_hour: 0.034333333333333334
per_day: 0.8240000000000001
per_month: 24.720000000000002
per_year: 300.76000000000005
per_request: .inf
resources:
auto_scaling_groups:
items:
tlap-demo-autoScalingGroup-19URKBUAGO3WB:
config:
instance_type: t2.nano
spot_price:
size:
min: 2
max: 2
avg: 1.1666666666666667
cost: 0.2240000000000001
usage:
memory_percentage:
min: 61.578199229834965
avg: 66.04526662297977
max: 72.2794131419596
cpu_percentage:
min: 2.5
avg: 8.089285714285714
max: 67.33
cost: 0.2240000000000001
load_balancers:
items:
tlap-demo-loadBala-DH21FTCDREX0:
usage:
hits:
sum: 0
average: 0
minimum: 0
maximum: 0
cost: 0.6
cost: 0.6
recommendations:
- elb 'tlap-demo-loadBala-DH21FTCDREX0' gets very little traffic ( 0.00 hits / hour).
Is this stack needed 24 hours a day? or at all?
Questions?
Feel free to ask for help when you look at the costs :)